 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDense2MoE: Pushing the Pareto Frontier of On-Device LLMs via Unified Pruning and Upcycling
May 26, 2026The Mixture of Experts MoE architecture is highly promising for resource constrained on device deployments yet training these models from scratch incurs prohibitive costs Current methods attempt to alleviate this by upcycling dense models into MoEs however they often introduce parameter redundancy that degrades inference efficiency Alternatively standard layer pruning mitigates redundancy but inevitably compromises model accuracy To resolve this dilemma we propose Dense2MoE a novel framework that unifies pruning and upcycling through Layer Fusion UpCycling LF UC Guided by hardware Roofline theory Dense2MoE systematically overcomes the inference memory wall by pruning bandwidth heavy attention modules from redundant layers while repurposing their Multi Layer Perceptrons MLPs into MoE experts This structural innovation preserves the models core capabilities and strictly limits active parameters via selective token routing With a modest continual pre training budget Dense2MoE efficiently converts publicly available dense LLMs into on device ready MoE models Extensive experiments demonstrate that Dense2MoE significantly advances the Pareto frontier for on device inference latency versus model accuracy outperforming dense baselines state of the art compression and standard upcycling methods
Hardware Co-Design Scaling Laws via Roofline Modelling for On-Device LLMs
Feb 10, 2026Vision-Language-Action Models (VLAs) have emerged as a key paradigm of Physical AI and are increasingly deployed in autonomous vehicles, robots, and smart spaces. In these resource-constrained on-device settings, selecting an appropriate large language model (LLM) backbone is a critical challenge: models must balance accuracy with strict inference latency and hardware efficiency constraints. This makes hardware-software co-design a game-changing requirement for on-device LLM deployment, where each hardware platform demands a tailored architectural solution. We propose a hardware co-design law that jointly captures model accuracy and inference performance. Specifically, we model training loss as an explicit function of architectural hyperparameters and characterise inference latency via roofline modelling. We empirically evaluate 1,942 candidate architectures on NVIDIA Jetson Orin, training 170 selected models for 10B tokens each to fit a scaling law relating architecture to training loss. By coupling this scaling law with latency modelling, we establish a direct accuracy-latency correspondence and identify the Pareto frontier for hardware co-designed LLMs. We further formulate architecture search as a joint optimisation over precision and performance, deriving feasible design regions under industrial hardware and application budgets. Our approach reduces architecture selection from months to days. At the same latency as Qwen2.5-0.5B on the target hardware, our co-designed architecture achieves 19.42% lower perplexity on WikiText-2. To our knowledge, this is the first principled and operational framework for hardware co-design scaling laws in on-device LLM deployment. We will make the code and related checkpoints publicly available.
SMAR: Soft Modality-Aware Routing Strategy for MoE-based Multimodal Large Language Models Preserving Language Capabilities
Jun 06, 2025Mixture of Experts (MoE) architectures have become a key approach for scaling large language models, with growing interest in extending them to multimodal tasks. Existing methods to build multimodal MoE models either incur high training costs or suffer from degraded language capabilities when adapting pretrained models. To address this, we propose Soft ModalityAware Routing (SMAR), a novel regularization technique that uses Kullback Leibler divergence to control routing probability distributions across modalities, encouraging expert specialization without modifying model architecture or heavily relying on textual data. Experiments on visual instruction tuning show that SMAR preserves language ability at 86.6% retention with only 2.5% pure text, outperforming baselines while maintaining strong multimodal performance. Our approach offers a practical and efficient solution to balance modality differentiation and language capabilities in multimodal MoE models.
GCsT: Graph Convolutional Skeleton Transformer for Action Recognition
Sep 10, 2021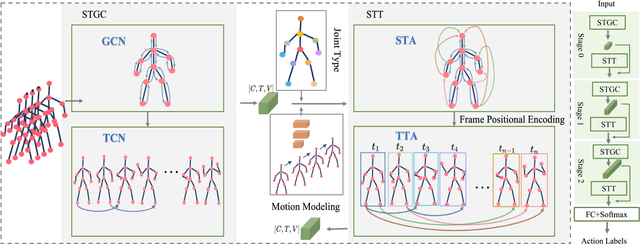
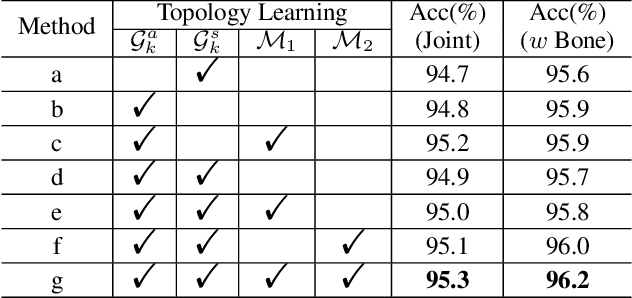
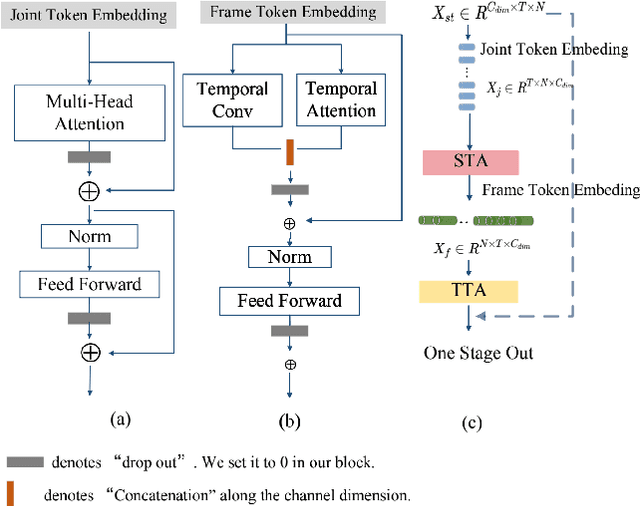
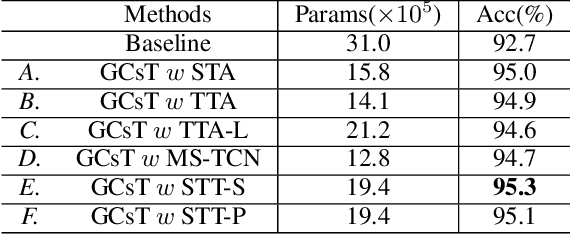
Graph convolutional networks (GCNs) achieve promising performance for skeleton-based action recognition. However, in most GCN-based methods, the spatial-temporal graph convolution is strictly restricted by the graph topology while only captures the short-term temporal context, thus lacking the flexibility of feature extraction. In this work, we present a novel architecture, named Graph Convolutional skeleton Transformer (GCsT), which addresses limitations in GCNs by introducing Transformer. Our GCsT employs all the benefits of Transformer (i.e. dynamical attention and global context) while keeps the advantages of GCNs (i.e. hierarchy and local topology structure). In GCsT, the spatial-temporal GCN forces the capture of local dependencies while Transformer dynamically extracts global spatial-temporal relationships. Furthermore, the proposed GCsT shows stronger expressive capability by adding additional information present in skeleton sequences. Incorporating the Transformer allows that information to be introduced into the model almost effortlessly. We validate the proposed GCsT by conducting extensive experiments, which achieves the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120 and Northwestern-UCLA datasets.